结构方程模型建模思路及Amos操作--基础准备
结构方程模型建模思路及Amos操作--基础准备
相信为什么要选择结构方程模型分析数据,大家心里面是有B数的,所以我就不说了。
问卷设计
一般而言,利用SEM分析的数据来源于问卷调查,当然也可以用其他的观察变量直接进行分析,比如说在经济领域建模,类似于资本、人力、投资等是可以直接观察的,不需要引入潜在变量,所以也不需要问卷进行数据收集,一般是有数据库这样子的。
问卷设计的时候,有一些小技巧
1.设计量表的时候,颗粒度分细一些,最好的李克特7级量表(LubkeMuthén, 2004)。别看国内大家平时都是用的李克特5级量表多一些,其实在SEM软件分析的时候,国外使用5级或者7级的量表进行数据收集的paper都比较多。并且,颗粒度越细,数据越容易服从多元正态分布,才能采用SEM内定的ML进行数据分析。但是记住,5级量表是最低要求,不能更低了。
2.万一没办法,你拿到的数据离散程度较差,成偏态,或者是见下图,二分类变量啊亲,可以采用Item parcel的方法,就是打包的意思,你按照自己的专业知识,如果问卷题目够多话,把好几道题的结果相加,即使样本上不大,达到一定稳定性,如果样本量较大,也可以解决这种无奈的问卷设计缺陷。
这本书Kenny D A. Correlation and causality.[M]// Correlation and causality. Wiley, 1979:e140-1.里面的第179页有告诉大家Item parcel的技巧。

3.原始问卷设计时每一个潜在变量要设计至少3题,5~7题为佳(Bollen, 1989)。有备则无患呐,万一跑程序的时候,发现一些题目的loading比较低,那还有得删除题目,以提高整个模型的匹适度。要是设计得每个潜在变量只有3道题,那真是没得删了。分析时先做EFA删除不要的题目,先用将loading0.6以下去除,再将cross-loading0.35以上删除。所以每一个潜在变量5~7题简直不能太棒!在正式的写在paper里面的文件,最好每个item要有4个题目比较好,因为3个题目没有办法做重置性检查、4个可以做误差相关、5个比4个好一点。4个最好。
关于第3点有一篇比较好的paper里面有介绍:Marsh H W, Hau K T, Balla J R, et al. Is
More Ever Too Much? The Number of Indicators per Factor in Confirmatory Factor
analysis[J]. Multivariate Behavioral Research, 1998, 33(2):181.
4.最少要有两个潜变量( Bollen, 1989),并且潜变量个数最好维持在5个以内,不要超过7个。同时每一个指标不得横跨到其他潜变量上,也就是说一个问题不要用来同时衡量两个潜变量。换言之,
Cross-loading0.4
Cross-loading同时属于多个潜变量的loading,如果大于0.4,表示横跨了2个因子,所以题目最好删除(Hair et al., 1998)。
5.量表最好不要自己设计,自设量表存在很多问题,就不赘述了,除非你是大牛,你是大牛就不会在这里逛B站了。哪怕是修改理论框架也要根据其他学者的理论和paper进行修改。
样本量确定
经验法则为每个预测变量用15个样本 (James Stevens, 1996)。
Bentler and Chou (1987) 提出样本数至少为估计参数的5倍(在服从正态,无遗漏变量值及极端值的情况下),否则要15倍的样本量。
Loehlin (1992)提出,一个有2至4个因素的模型,至少100个样本,200个更好, 小样本容易导致收敛失败、不适当的解(违犯估计) 、低估参数值及错误的标准误等。
一般而言,大于200以上的样本,才可以称得上是一个中型的样本,若要追求稳定的SEM分析结果,受试样本量最好在200以上。
虽然SEM的分析以大样本数量较佳,但较新的统计检验方法允许SEM模型的估计可少于60个观察值(TabachnickFidell,2007)。
港真,样本量还是越大越好,除非你有正当理由说明你的样本量实在是特别非常之难收集的情况下,比如说同性恋群体,或者是某种稀少的患病人群,辣么,最好还是400+,现在微信发问卷也不是分分钟就可以好几千的样本。
哦,有些时候如果觉得大学生群体的样本比较容易获得,但是担心样本量有偏性,这里有个段子,前段时间去参加一个论坛的时候,苏毓淞老师就用的大学生样本,然后他吐槽说,所谓的大家认为大学生群体是现在的精英群体,是真的吗?当代大学生的质量真的可以称之为“精英群体”吗?哈哈哈,笑死我了,现在大学生这么多,别太担心样本偏性啦。当然paper里面不能这么写,心里面知道就好了。
还有就是一般来说,如果题目越多那么样本数应该越大,如果一开始发现样本量不能太多,建议把indicator增加,以增加客观性。
选择参数估计方法
ML(极大似然法):只有样本是大样本并且假设观察数据服从多元正太分布,卡方检验才可以合理使用,此时使用ML估计法最为合适。ML比ULS有效率,因为可以得到较小的标准误。
GLS(一般化最小平方法):如果样本为大样本,但观察数据不服从多元正太分布,最好采用GLS估计法(周子敬,2006)。GLS和ULS均是全信息估计方法,但是ULS需要所需的观察尺度相同。GLS是WLS(ADF)的一条分支。
IV法(工具性变量法)、TSLS法(两阶段最小平方法)属于快速、非递归、有限信息技术的估计方法。
WLS法和DWLS法不像GLS法与ML法,受到数据须符合多元正太的假定限制,但为了使估计结果可以收敛,WLS法和DWLS法的运算需要非常大的样本量,一般在1000+。当数据非正太,无法使用ML法和GLS法估计参数时,才考虑WLS、DWLS法(Diamantopoulos Siguaw,2000)。
贝叶斯估计:ML法较不适用于小样本,小样本使用贝叶斯估计(P27),贝叶斯估计需要在分析属性中选取估计平均数和截距。
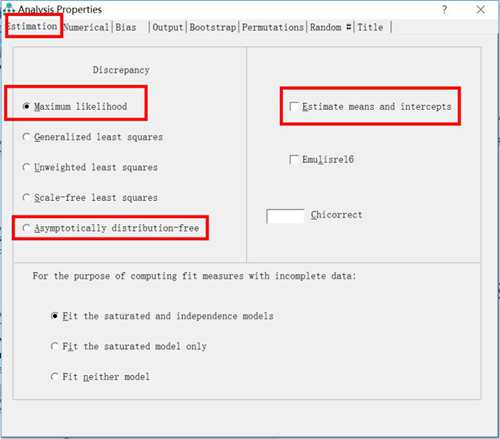
ADF法:下图是Amos的估计,里面的ML估计是default,当样本量超过1000时,并且资料不服从正太分布时,可以选择标红的Asymptotically distribution-free
只有三种情况才需要选择估计均值和截距(estimate means and intercepts):1.资料有缺失值;2.资料为时序型资料;3.进行anova分析或者manova分析。
开始数据分析啦,以我自己的某一次操作为例
楼主的数据来源于课题,就是刚才截图里面一言难尽的2分类变量,当然题主的自主课题自己设计问卷就没有出现这么乌龙的事情,但是有了数据,不想方设法加以利用就是浪费,浪费可耻。
首先的话,题主接触到的就是一张看上去很复杂的问卷,以及已经收集好了的1W+样本。这里歪个楼说一下,这么大的样本量,收集过程又及其严苛,花费了大量的人力、物力、精力,无论是问卷的设计,样本的收集还是说录入、清洗,无疑都是巨大的工程量。
第一步:所以我采用的是item parcel的方法,把好几个问题打包成为一个问题,这里还是很艰难,因为类似于5个原始问卷的题目才能凑成一个有用的SEM 题目,所以问卷的题量很不够用。所以一些维度肯定不服从正太了,这里就不能用ML进行分析了。
第二步:进行建模构建
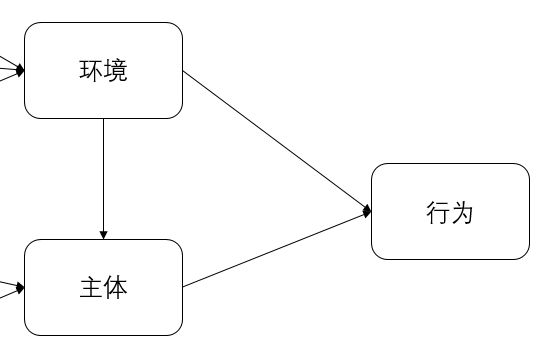
这里强调,希望大家不要随意建模,当然探索性是鼓励的,最好还是要有前人的研究基础,有理论基础,证明你这样建立是有原因的,是可靠的,有依据的。题主根据自己的研究,采用了社会认知理论,见下图,只有三个变量,是最简单的了,题主也想用复杂一点,炫酷一点的模型,但是匹配最理想的模型还是社会认知理论。
第三步:数据处理
因为样本量很大,所以我可以把缺失值都给删了。
第四步:跑AMOS
打开amos,双击打开
导入数据,我用的这版amos特别蠢,直接导入Excel容易出错。所以还是把Excel文件转换成为SPSS格式的,更容易被Amos识别。
按照理论和问卷数量,设计模型,一个小方格代表一个问题。
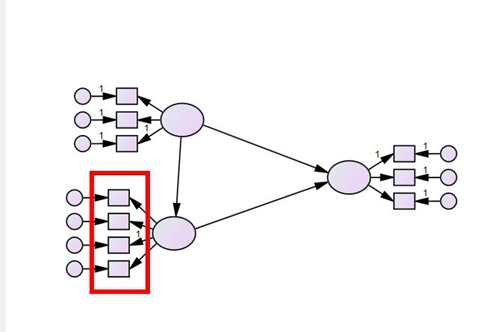
导入问题进入
导入以后变成这样

给潜变量命名,双击中间那三个圆圈就可以了,在variable name那里分别输入环境、主体和行为意图。
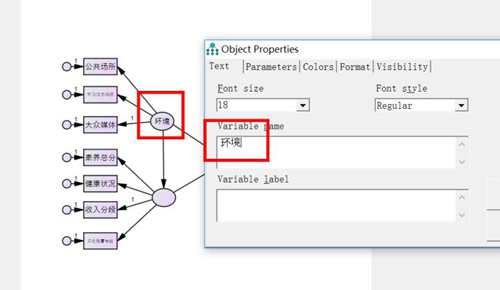
命名完成以后长这样
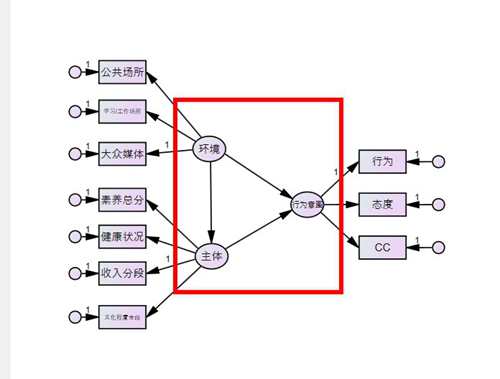
给残差命名,选择plugins-name unobserved variables,就可以一次性给残差命名啦
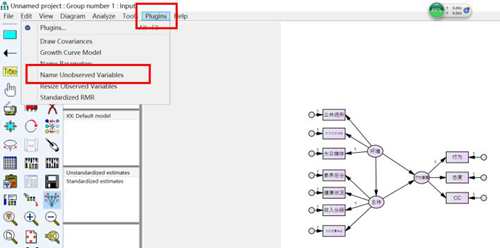
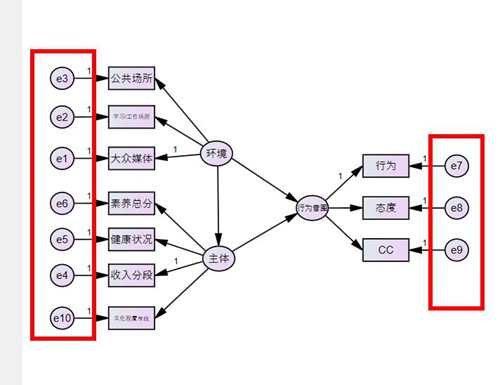
命名完成以后,长这样,e1到e10自动命名的
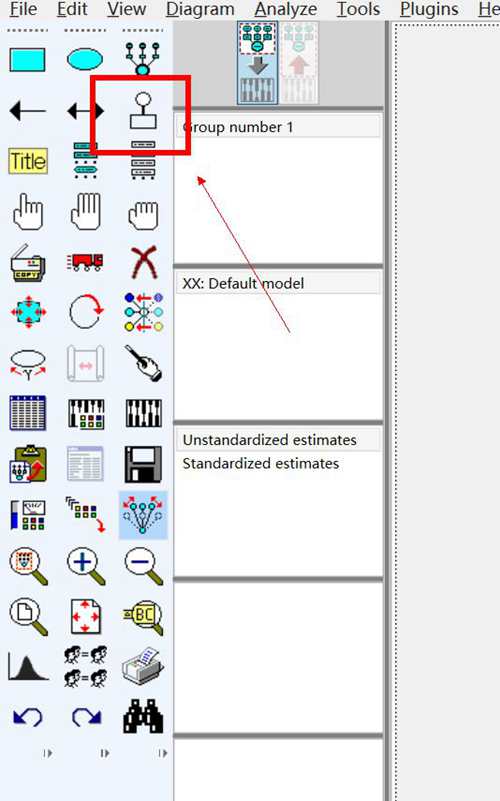
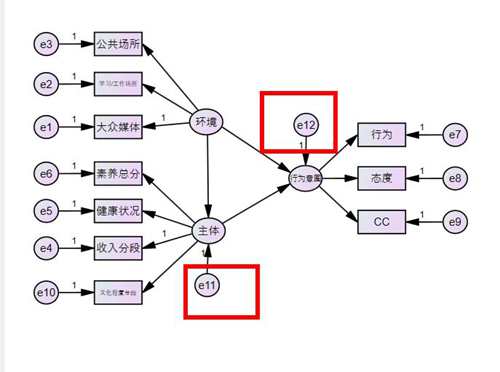
给“主体”和“行为意图”添加unique variable,见下图,点击这个按钮,然后在“主体”变量和“行为意图”变量上各点击一次,再进行残差命名哈。
完成以后长这样,完整的模型就构建成功啦。
把模型保存好,当然就是下面这颗按钮啦
运行模型,点击这个长得像算盘一样的按钮。
不太理想结果就跑出来啦,那些教学的,一跑数据各项指标都符合,那是骗你的,更多时候就像我这样,不太理想的结果。
依次解释为reading data 读写数据
4435个样本
默认模型
采用最小化方法迭代
迭代了15次
卡方值为1686.1 自由度为32

这时候得找原因了,刚才说过了,这个数据是偏态的,不应该使用ML,默认的分析,应该采用GLS或者WLS,详情见上面我写的分析方法的选择。
这里开始选择GLS,点击这个按钮,analysis properties,分析属性
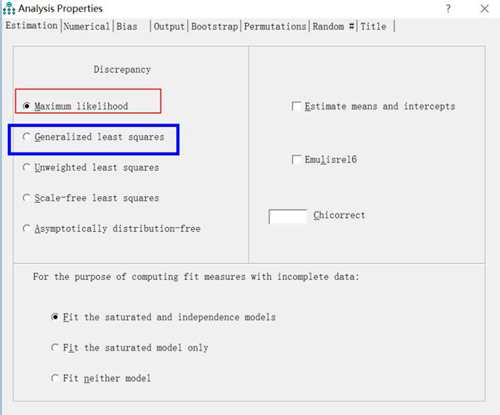
默认是第一个ML,这里我们要选择第二个,GLS
output,输出选择,还是在刚才那个界面,点击output
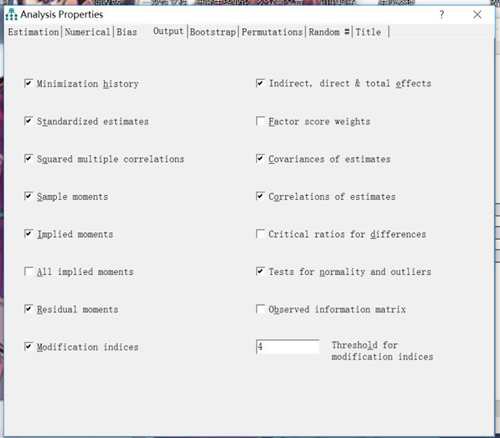
默认的只有最小化过程这个选项,我们要选择其他的,比如说直接、间接、总效应,样本矩阵,隐含矩阵,修正指标等,见下下图。
从左到右依次是
最小化过程 minimization history
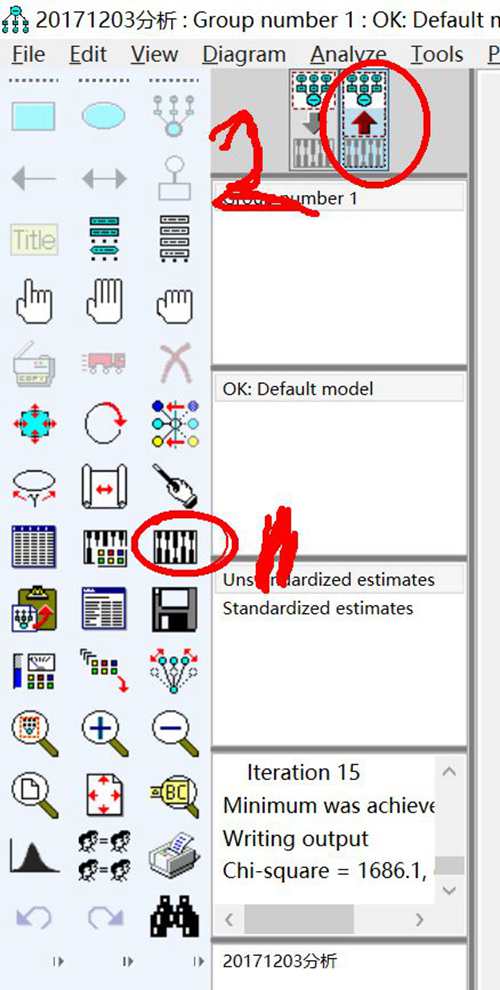
标准化的估计值 standardized estimates
多元相关的平方 squared multiple estimates 好像这个也是多重线性回归里面的R方
间接效应,直接效应、总效应 indirect,direct,total effects
样本协方差矩阵 sample moments
隐含协方差矩阵 implied moments
残差矩阵 residual moments
修正指标 modification indices
检验正态性和异常值 tests for normality and outlies
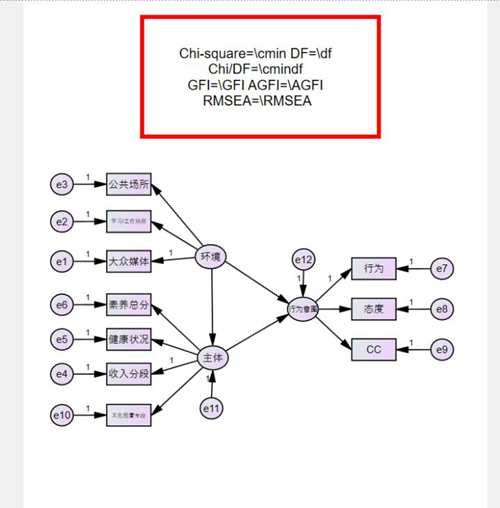
输入title 和一些常见的匹适度检验指标,随意在空白的地方点击右键,然后选择figure caption,再点击一下白色空白部分
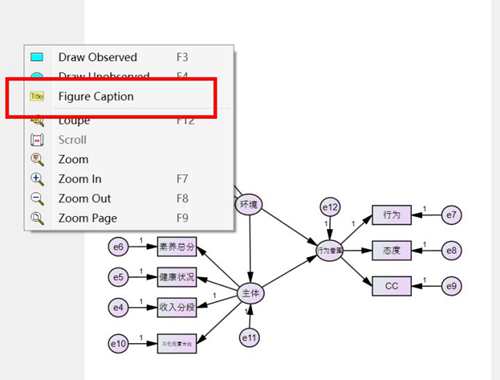
在caption 空白的地方把以下指令输进去
Chi-square=cmin DF=df
Chi/DF=cmindf
GFI=GFI AGFI=AGFI
RMSEA=RMSEA
点击OK关掉对话框
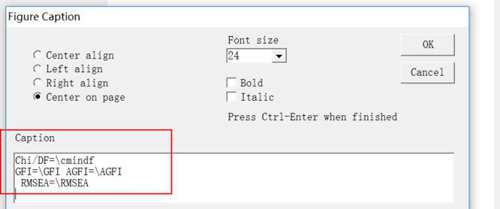
效果图见下
点击运行和结果,分别点以下按钮
非标准化的结果运行如下图。结果很不理想。
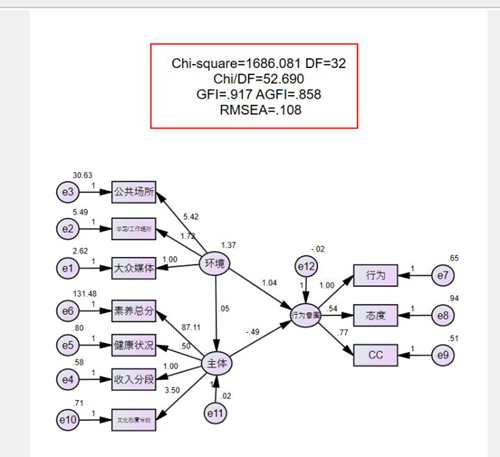
卡方/自由度=52.56,Chi-square/DF 要在3以内才算理想
Gfi agfi 要大于0.9,这个满足
Rmsea小于0.08,0.05是理想值,这个值也很不理想。
总之,就是匹适度很低的意思。
配适度低的原因
造成匹适度差的原因有:变量间的非线性关系,缺失值太多、序列误差,残差不独立。
序列误差:从模型中遗漏了适当的外衍变量、变量间的重要连接路径,或模型中包含不适当的联结关系等。
文章太长了,剩下的其他篇章再说。
以上就是(结构方程模型建模思路及Amos操作--基础准备)全部内容,收藏起来下次访问不迷路!